Statistics
Statistics
Jump to year
Paper 1, Section I, H
Let be i.i.d. Bernoulli random variables, where and is unknown.
(a) What does it mean for a statistic to be sufficient for ? Find such a sufficient statistic .
(b) State and prove the Rao-Blackwell theorem.
(c) By considering the estimator of , find an unbiased estimator of that is a function of the statistic found in part (a), and has variance strictly smaller than that of .
Paper 1, Section II, H
(a) Show that if are independent random variables with common distribution, then . [Hint: If then if and otherwise.]
(b) Show that if then .
(c) State the Neyman-Pearson lemma.
(d) Let be independent random variables with common density proportional to for . Find a most powerful test of size of against , giving the critical region in terms of a quantile of an appropriate gamma distribution. Find a uniformly most powerful test of size of against .
Paper 2, Section I,
The efficacy of a new drug was tested as follows. Fifty patients were given the drug, and another fifty patients were given a placebo. A week later, the numbers of patients whose symptoms had gone entirely, improved, stayed the same and got worse were recorded, as summarised in the following table.
\begin{tabular}{|c|c|c|} \hline & Drug & Placebo \ \hline symptoms gone & 14 & 6 \ improved & 21 & 19 \ same & 10 & 10 \ worse & 5 & 15 \ \hline \end{tabular}
Conduct a significance level test of the null hypothesis that the medicine and placebo have the same effect, against the alternative that their effects differ.
[Hint: You may find some of the following values relevant:
\begin{tabular}{|c|cccccc|} \hline Distribution & & & & & & \ \hline 95 th percentile & & & & & & \ \hline \end{tabular}
Paper 3, Section II,
Consider the normal linear model where is a known design matrix with is an unknown vector of parameters, and is a vector of normal errors with each component having variance . Suppose has full column rank.
(i) Write down the maximum likelihood estimators, and , for and respectively. [You need not derive these.]
(ii) Show that is independent of .
(iii) Find the distributions of and .
(iv) Consider the following test statistic for testing the null hypothesis against the alternative :
Let be the eigenvalues of . Show that under has the same distribution as
where and are independent random variables, independent of .
[Hint: You may use the fact that where has orthonormal columns, is an orthogonal matrix and is a diagonal matrix with
(v) Find when . [Hint: If with , then .]
Paper 4, Section II,
Suppose we wish to estimate the probability that a potentially biased coin lands heads up when tossed. After independent tosses, we observe heads.
(a) Write down the maximum likelihood estimator of .
(b) Find the mean squared error of as a function of . Compute .
(c) Suppose a uniform prior is placed on . Find the Bayes estimator of under squared error loss .
(d) Now find the Bayes estimator under the , where . Show that
where and depend on and .
(e) Determine the mean squared error of as defined by .
(f) For what range of values of do we have ?
[Hint: The mean of a Beta distribution is and its density at is , where is a normalising constant.]
Paper 1, Section I,
Suppose are independent with distribution . Suppose a prior is placed on the unknown parameter for some given deterministic and . Derive the posterior mean.
Find an expression for the mean squared error of this posterior mean when .
Paper 1, Section II, H
Let be i.i.d. random variables, where is unknown.
(a) Derive the maximum likelihood estimator of .
(b) What is a sufficient statistic? What is a minimal sufficient statistic? Is sufficient for ? Is it minimal sufficient? Answer the same questions for the sample mean . Briefly justify your answers.
[You may use any result from the course provided it is stated clearly.]
(c) Show that the mean squared errors of and are respectively
(d) Show that for each for a function you should specify. Give, with justification, an approximate confidence interval for whose expected length is
[Hint: for all .]
Paper 2, Section II, H
Consider the general linear model where is a known design matrix with is an unknown vector of parameters, and is a vector of stochastic errors with and for all with . Suppose has full column rank.
(a) Write down the least squares estimate of and show that it minimises the least squares objective over .
(b) Write down the variance-covariance matrix .
(c) Let minimise over subject to . Let be the submatrix of that excludes the final column. Write .
(d) Let and be orthogonal projections onto the column spaces of and respectively. Show that for all .
(e) Show that for all ,
[Hint: Argue that for some .]
Paper 1, Section I, H
Suppose that are i.i.d. random variables.
(a) Compute the MLEs for the unknown parameters .
(b) Give the definition of an unbiased estimator. Determine whether are unbiased estimators for .
Paper 1, Section II, H
State and prove the Neyman-Pearson lemma.
Suppose that are i.i.d. random variables where is an unknown parameter. We wish to test the hypothesis against the hypothesis where .
(a) Find the critical region of the likelihood ratio test of size in terms of the sample mean .
(b) Define the power function of a hypothesis test and identify the power function in the setting described above in terms of the probability distribution function. [You may use without proof that is distributed as a random variable.]
(c) Define what it means for a hypothesis test to be uniformly most powerful. Determine whether the likelihood ratio test considered above is uniformly most powerful for testing against .
Paper 2, Section I, H
Suppose that are i.i.d. coin tosses with probability of obtaining a head.
(a) Compute the posterior distribution of given the observations in the case of a uniform prior on .
(b) Give the definition of the quadratic error loss function.
(c) Determine the value of which minimizes the quadratic error loss function. Justify your answer. Calculate .
[You may use that the , distribution has density function on given by
where is a normalizing constant. You may also use without proof that the mean of a random variable is
Paper 3, Section II, H
Suppose that are i.i.d. . Let
(a) Compute the distributions of and and show that and are independent.
(b) Write down the distribution of .
(c) For , find a confidence interval in each of the following situations: (i) for when is known; (ii) for when is not known; (iii) for when is not known.
(d) Suppose that are i.i.d. . Explain how you would use the test to test the hypothesis against the hypothesis . Does the test depend on whether are known?
Paper 4, Section II, 19H
Consider the linear model
where are known and are i.i.d. . We assume that the parameters and are unknown.
(a) Find the MLE of . Explain why is the same as the least squares estimator of .
(b) State and prove the Gauss-Markov theorem for this model.
(c) For each value of with , determine the unbiased linear estimator of which minimizes
Paper 1, Section I, H
form a random sample from a distribution whose probability density function is
where the value of the positive parameter is unknown. Determine the maximum likelihood estimator of the median of this distribution.
Paper 1, Section II, H
(a) Consider the general linear model where is a known matrix, is an unknown vector of parameters, and is an vector of independent random variables with unknown variances . Show that, provided the matrix is of rank , the least squares estimate of is
Let
What is the distribution of ? Write down, in terms of , an unbiased estimator of .
(b) Four points on the ground form the vertices of a plane quadrilateral with interior angles , so that . Aerial observations are made of these angles, where the observations are subject to independent errors distributed as random variables.
(i) Represent the preceding model as a general linear model with observations and unknown parameters .
(ii) Find the least squares estimates .
(iii) Determine an unbiased estimator of . What is its distribution?
Paper 2, Section I,
Define a simple hypothesis. Define the terms size and power for a test of one simple hypothesis against another. State the Neyman-Pearson lemma.
There is a single observation of a random variable which has a probability density function . Construct a best test of size for the null hypothesis
against the alternative hypothesis
Calculate the power of your test.
Paper 3, Section II, H
A treatment is suggested for a particular illness. The results of treating a number of patients chosen at random from those in a hospital suffering from the illness are shown in the following table, in which the entries are numbers of patients.
Describe the use of Pearson's statistic in testing whether the treatment affects recovery, and outline a justification derived from the generalised likelihood ratio statistic. Show that
[Hint: You may find it helpful to observe that
Comment on the use of this statistical technique when
Paper 4, Section II, H
There is widespread agreement amongst the managers of the Reliable Motor Company that the number of faulty cars produced in a month has a binomial distribution
where is the total number of cars produced in a month. There is, however, some dispute about the parameter . The general manager has a prior distribution for which is uniform, while the more pessimistic production manager has a prior distribution with density , both on the interval .
In a particular month, faulty cars are produced. Show that if the general manager's loss function is , where is her estimate and the true value, then her best estimate of is
The production manager has responsibilities different from those of the general manager, and a different loss function given by . Find his best estimate of and show that it is greater than that of the general manager unless .
[You may use the fact that for non-negative integers ,
Paper 1, Section I, H
(a) State and prove the Rao-Blackwell theorem.
(b) Let be an independent sample from with to be estimated. Show that is an unbiased estimator of and that is a sufficient statistic.
What is
Paper 1, Section II, H
(a) Give the definitions of a sufficient and a minimal sufficient statistic for an unknown parameter .
Let be an independent sample from the geometric distribution with success probability and mean , i.e. with probability mass function
Find a minimal sufficient statistic for . Is your statistic a biased estimator of
[You may use results from the course provided you state them clearly.]
(b) Define the bias of an estimator. What does it mean for an estimator to be unbiased?
Suppose that has the truncated Poisson distribution with probability mass function
Show that the only unbiased estimator of based on is obtained by taking if is odd and if is even.
Is this a useful estimator? Justify your answer.
Paper 2, Section I, 8H
(a) Define a confidence interval for an unknown parameter .
(b) Let be i.i.d. random variables with distribution with unknown. Find a confidence interval for .
[You may use the fact that
(c) Let be independent with to be estimated. Find a confidence interval for .
Suppose that we have two observations and . What might be a better interval to report in this case?
Paper 3, Section II,
Consider the general linear model
where is a known matrix of full rank with known and is an unknown vector.
(a) State without proof the Gauss-Markov theorem.
Find the maximum likelihood estimator for . Is it unbiased?
Let be any unbiased estimator for which is linear in . Show that
for all .
(b) Suppose now that and that and are both unknown. Find the maximum likelihood estimator for . What is the joint distribution of and in this case? Justify your answer.
Paper 4, Section II, H
(a) State and prove the Neyman-Pearson lemma.
(b) Let be a real random variable with density with
Find a most powerful test of size of versus .
Find a uniformly most powerful test of size of versus .
Paper 1, Section I, H
Let be independent samples from the exponential distribution with density for , where is an unknown parameter. Find the critical region of the most powerful test of size for the hypotheses versus . Determine whether or not this test is uniformly most powerful for testing versus .
Paper 1, Section II, H
(a) What does it mean to say a statistic is sufficient for an unknown parameter ? State the factorisation criterion for sufficiency and prove it in the discrete case.
(b) State and prove the Rao-Blackwell theorem.
(c) Let be independent samples from the uniform distribution on for an unknown positive parameter . Consider the two-dimensional statistic
Prove that is sufficient for . Determine, with proof, whether or not is minimally sufficient.
Paper 2, Section I, H
The efficacy of a new medicine was tested as follows. Fifty patients were given the medicine, and another fifty patients were given a placebo. A week later, the number of patients who got better, stayed the same, or got worse was recorded, as summarised in this table:
\begin{tabular}{|l|c|c|} \hline & medicine & placebo \ better & 28 & 22 \ same & 4 & 16 \ worse & 18 & 12 \ \hline \end{tabular}
Conduct a Pearson chi-squared test of size of the hypothesis that the medicine and the placebo have the same effect.
[Hint: You may find the following values relevant:
Paper 3, Section II, H
Let be independent samples from the Poisson distribution with mean .
(a) Compute the maximum likelihood estimator of . Is this estimator biased?
(b) Under the assumption that is very large, use the central limit theorem to find an approximate confidence interval for . [You may use the notation for the number such that for a standard normal
(c) Now suppose the parameter has the prior distribution. What is the posterior distribution? What is the Bayes point estimator for for the quadratic loss function Let be another independent sample from the same distribution. Given , what is the posterior probability that ?
[Hint: The density of the distribution is , for .]
Paper 4, Section II, H
Consider the linear regression model
for , where the non-zero numbers are known and are such that , the independent random variables have the distribution, and the parameters and are unknown.
(a) Let be the maximum likelihood estimator of . Prove that for each , the random variables and are uncorrelated. Using standard facts about the multivariate normal distribution, prove that and are independent.
(b) Find the critical region of the generalised likelihood ratio test of size for testing versus . Prove that the power function of this test is of the form for some function . [You are not required to find explicitly.]
Paper 1, Section I, H
Suppose that are independent normally distributed random variables, each with mean and variance 1 , and consider testing against . Explain what is meant by the critical region, the size and the power of a test.
For , derive the test that is most powerful among all tests of size at most . Obtain an expression for the power of your test in terms of the standard normal distribution function .
[Results from the course may be used without proof provided they are clearly stated.]
Paper 1, Section II, H
Suppose are independent identically distributed random variables each with probability mass function , where is an unknown parameter. State what is meant by a sufficient statistic for . State the factorisation criterion for a sufficient statistic. State and prove the Rao-Blackwell theorem.
Suppose that are independent identically distributed random variables with
where is a known positive integer and is unknown. Show that is unbiased for .
Show that is sufficient for and use the Rao-Blackwell theorem to find another unbiased estimator for , giving details of your derivation. Calculate the variance of and compare it to the variance of .
A statistician cannot remember the exact statement of the Rao-Blackwell theorem and calculates in an attempt to find an estimator of . Comment on the suitability or otherwise of this approach, giving your reasons.
[Hint: If and are positive integers then, for
Paper 2, Section I, H
Suppose that, given , the random variable has , Suppose that the prior density of is , for some known . Derive the posterior density of based on the observation .
For a given loss function , a statistician wants to calculate the value of that minimises the expected posterior loss
Suppose that . Find in terms of in the following cases:
(a) ;
(b) .
Paper 3, Section II, H
(a) Suppose that are independent identically distributed random variables, each with density for some unknown . Use the generalised likelihood ratio to obtain a size test of against .
(b) A die is loaded so that, if is the probability of face , then , and . The die is thrown times and face is observed times. Write down the likelihood function for and find the maximum likelihood estimate of .
Consider testing whether or not for this die. Find the generalised likelihood ratio statistic and show that
where you should specify and in terms of . Explain how to obtain an approximate size test using the value of . Explain what you would conclude (and why ) if .
Paper 4, Section II, H
Consider a linear model where is an vector of observations, is a known matrix, is a vector of unknown parameters and is an vector of independent normally distributed random variables each with mean zero and unknown variance . Write down the log-likelihood and show that the maximum likelihood estimators and of and respectively satisfy
denotes the transpose . Assuming that is invertible, find the solutions and of these equations and write down their distributions.
Prove that and are independent.
Consider the model and . Suppose that, for all and , and that , are independent random variables where is unknown. Show how this model may be written as a linear model and write down and . Find the maximum likelihood estimators of and in terms of the . Derive a confidence interval for and for .
[You may assume that, if is multivariate normal with , then and are independent.]
Paper 1, Section I,
Consider an estimator of an unknown parameter , and assume that for all . Define the bias and mean squared error of .
Show that the mean squared error of is the sum of its variance and the square of its bias.
Suppose that are independent identically distributed random variables with mean and variance , and consider estimators of of the form where .
(i) Find the value of that gives an unbiased estimator, and show that the mean squared error of this unbiased estimator is .
(ii) Find the range of values of for which the mean squared error of is smaller .
Paper 1, Section II, H
Suppose that , and are independent identically distributed Poisson random variables with expectation , so that
and consider testing against , where is a known value greater than 1. Show that the test with critical region is a likelihood ratio test of against . What is the size of this test? Write down an expression for its power.
A scientist counts the number of bird territories in randomly selected sections of a large park. Let be the number of bird territories in the th section, and suppose that are independent Poisson random variables with expectations respectively. Let be the area of the th section. Suppose that , and . Derive the generalised likelihood ratio for testing
What should the scientist conclude about the number of bird territories if is
[Hint: Let be where has a Poisson distribution with expectation . Then
Paper 2, Section I, H
There are 100 patients taking part in a trial of a new surgical procedure for a particular medical condition. Of these, 50 patients are randomly selected to receive the new procedure and the remaining 50 receive the old procedure. Six months later, a doctor assesses whether or not each patient has fully recovered. The results are shown below:
\begin{tabular}{l|c|c} & Fully recovered & Not fully recovered \ \hline Old procedure & 25 & 25 \ \hline New procedure & 31 & 19 \end{tabular}
The doctor is interested in whether there is a difference in full recovery rates for patients receiving the two procedures. Carry out an appropriate significance level test, stating your hypotheses carefully. [You do not need to derive the test.] What conclusion should be reported to the doctor?
[Hint: Let denote the upper percentage point of a distribution. Then
Paper 3, Section II, H
Suppose that are independent identically distributed random variables with
where is known and is an unknown parameter. Find the maximum likelihood estimator of .
Statistician 1 has prior density for given by , where . Find the posterior distribution for after observing data . Write down the posterior mean , and show that
where depends only on the prior distribution and is a constant in that is to be specified.
Statistician 2 has prior density for given by . Briefly describe the prior beliefs that the two statisticians hold about . Find the posterior mean and show that .
Suppose that increases (but and the remain unchanged). How do the prior beliefs of the two statisticians change? How does vary? Explain briefly what happens to and .
[Hint: The Beta distribution has density
with expectation and variance . Here, , is the Gamma function.]
Paper 4, Section II, H
Consider a linear model
where is a known matrix, is a vector of unknown parameters and is an vector of independent random variables with unknown. Assume that has full rank . Find the least squares estimator of and derive its distribution. Define the residual sum of squares and write down an unbiased estimator of .
Suppose that and , for , where and are known with , and are independent random variables. Assume that at least two of the are distinct and at least two of the are distinct. Show that (where denotes transpose) may be written as in ( ) and identify and . Find in terms of the , and . Find the distribution of and derive a confidence interval for .
[Hint: You may assume that has a distribution, and that and the residual sum of squares are independent. Properties of distributions may be used without proof.]
Paper 1, Section I, H
Let be independent and identically distributed observations from a distribution with probability density function
where and are unknown positive parameters. Let . Find the maximum likelihood estimators and .
Determine for each of and whether or not it has a positive bias.
Paper 1, Section II, H
Consider the general linear model where is a known matrix, is an unknown vector of parameters, and is an vector of independent random variables with unknown variance . Assume the matrix is invertible. Let
What are the distributions of and ? Show that and are uncorrelated.
Four apple trees stand in a rectangular grid. The annual yield of the tree at coordinate conforms to the model
where is the amount of fertilizer applied to tree may differ because of varying soil across rows, and the are random variables that are independent of one another and from year to year. The following two possible experiments are to be compared:
Represent these as general linear models, with . Compare the variances of estimates of under I and II.
With II the following yields are observed:
Forecast the total yield that will be obtained next year if no fertilizer is used. What is the predictive interval for this yield?
Paper 2, Section I, H
State and prove the Rao-Blackwell theorem.
Individuals in a population are independently of three types , with unknown probabilities where . In a random sample of people the th person is found to be of type .
Show that an unbiased estimator of is
Suppose that of the individuals are of type . Find an unbiased estimator of , say , such that .
Paper 3, Section II, H
Suppose is a single observation from a distribution with density over . It is desired to test against .
Let define a test by 'accept '. Let . State the Neyman-Pearson lemma using this notation.
Let be the best test of size . Find and .
Consider now where means 'declare the test to be inconclusive'. Let . Given prior probabilities for and for , and some , let
Let , where . Prove that for each value of there exist (depending on such that Hint
Hence prove that if is any test for which
then and .
Paper 4, Section II, H
Explain the notion of a sufficient statistic.
Suppose is a random variable with distribution taking values in , with . Let be a sample from . Suppose is the number of these that are equal to . Use a factorization criterion to explain why is sufficient for .
Let be the hypothesis that for all . Derive the statistic of the generalized likelihood ratio test of against the alternative that this is not a good fit.
Assuming that when is true and is large, show that this test can be approximated by a chi-squared test using a test statistic
Suppose and . Would you reject Explain your answer.
Paper 1, Section I, H
Describe the generalised likelihood ratio test and the type of statistical question for which it is useful.
Suppose that are independent and identically distributed random variables with the Gamma distribution, having density function . Similarly, are independent and identically distributed with the Gamma distribution. It is desired to test the hypothesis against . Derive the generalised likelihood ratio test and express it in terms of .
Let denote the value that a random variable having the distribution exceeds with probability . Explain how to decide the outcome of a size test when by knowing only the value of and the value , for some and , which you should specify.
[You may use the fact that the distribution is equivalent to the distribution.]
Paper 1, Section II, H
State and prove the Neyman-Pearson lemma.
A sample of two independent observations, , is taken from a distribution with density . It is desired to test against . Show that the best test of size can be expressed using the number such that
Is this the uniformly most powerful test of size for testing against
Suppose that the prior distribution of is , where . Find the test of against that minimizes the probability of error.
Let denote the power function of this test at . Show that
Paper 2, Section I, H
Let the sample have likelihood function . What does it mean to say is a sufficient statistic for ?
Show that if a certain factorization criterion is satisfied then is sufficient for .
Suppose that is sufficient for and there exist two samples, and , for which and does not depend on . Let
Show that is also sufficient for .
Explain why is not minimally sufficient for .
Paper 3, Section II, H
Suppose that is a single observation drawn from the uniform distribution on the interval , where is unknown and might be any real number. Given we wish to test against . Let be the test which accepts if and only if , where
Show that this test has size .
Now consider
Prove that both and specify confidence intervals for . Find the confidence interval specified by when .
Let be the length of the confidence interval specified by . Let be the probability of the Type II error of . Show that
Here is an indicator variable for event . The expectation is over . [Orders of integration and expectation can be interchanged.]
Use what you know about constructing best tests to explain which of the two confidence intervals has the smaller expected length when .
Paper 4, Section II, H
From each of 3 populations, data points are sampled and these are believed to obey
where , the are independent and identically distributed as , and is unknown. Let .
(i) Find expressions for and , the least squares estimates of and .
(ii) What are the distributions of and ?
(iii) Show that the residual sum of squares, , is given by
Calculate when ,
(iv) is the hypothesis that . Find an expression for the maximum likelihood estimator of under the assumption that is true. Calculate its value for the above data.
(v) Explain (stating without proof any relevant theory) the rationale for a statistic which can be referred to an distribution to test against the alternative that it is not true. What should be the degrees of freedom of this distribution? What would be the outcome of a size test of with the above data?
Paper 1, Section I,
Consider the experiment of tossing a coin times. Assume that the tosses are independent and the coin is biased, with unknown probability of heads and of tails. A total of heads is observed.
(i) What is the maximum likelihood estimator of ?
Now suppose that a Bayesian statistician has the prior distribution for .
(ii) What is the posterior distribution for ?
(iii) Assuming the loss function is , show that the statistician's point estimate for is given by
[The distribution has density for and
Paper 1, Section II, H
Let be independent random variables with probability mass function , where is an unknown parameter.
(i) What does it mean to say that is a sufficient statistic for ? State, but do not prove, the factorisation criterion for sufficiency.
(ii) State and prove the Rao-Blackwell theorem.
Now consider the case where for non-negative integer and .
(iii) Find a one-dimensional sufficient statistic for .
(iv) Show that is an unbiased estimator of .
(v) Find another unbiased estimator which is a function of the sufficient statistic and that has smaller variance than . You may use the following fact without proof: has the Poisson distribution with parameter .
Paper 2, Section I, H
Let be random variables with joint density function , where is an unknown parameter. The null hypothesis is to be tested against the alternative hypothesis .
(i) Define the following terms: critical region, Type I error, Type II error, size, power.
(ii) State and prove the Neyman-Pearson lemma.
Paper 3, Section II, H
Consider the general linear model
where is a known matrix, is an unknown vector of parameters, and is an vector of independent random variables with unknown variance . Assume the matrix is invertible.
(i) Derive the least squares estimator of .
(ii) Derive the distribution of . Is an unbiased estimator of ?
(iii) Show that has the distribution with degrees of freedom, where is to be determined.
(iv) Let be an unbiased estimator of of the form for some matrix . By considering the matrix or otherwise, show that and are independent.
[You may use standard facts about the multivariate normal distribution as well as results from linear algebra, including the fact that is a projection matrix of rank , as long as they are carefully stated.]
Paper 4, Section II, H
Consider independent random variables with the distribution and with the distribution, where the means and variances are unknown. Derive the generalised likelihood ratio test of size of the null hypothesis against the alternative . Express the critical region in terms of the statistic and the quantiles of a beta distribution, where
[You may use the following fact: if and are independent, then
Paper 1, Section I, E
Suppose are independent random variables, where is an unknown parameter. Explain carefully how to construct the uniformly most powerful test of size for the hypothesis versus the alternative .
Paper 1, Section II, E
Consider the the linear regression model
where the numbers are known, the independent random variables have the distribution, and the parameters and are unknown. Find the maximum likelihood estimator for .
State and prove the Gauss-Markov theorem in the context of this model.
Write down the distribution of an arbitrary linear estimator for . Hence show that there exists a linear, unbiased estimator for such that
for all linear, unbiased estimators .
[Hint: If then
Paper 2, Section I, E
A washing powder manufacturer wants to determine the effectiveness of a television advertisement. Before the advertisement is shown, a pollster asks 100 randomly chosen people which of the three most popular washing powders, labelled and , they prefer. After the advertisement is shown, another 100 randomly chosen people (not the same as before) are asked the same question. The results are summarized below.
\begin{tabular}{c|ccc} & & & \ \hline before & 36 & 47 & 17 \ after & 44 & 33 & 23 \end{tabular}
Derive and carry out an appropriate test at the significance level of the hypothesis that the advertisement has had no effect on people's preferences.
[You may find the following table helpful:
Paper 3, Section II, E
Let be independent random variables with unknown parameter . Find the maximum likelihood estimator of , and state the distribution of . Show that has the distribution. Find the confidence interval for of the form for a constant depending on .
Now, taking a Bayesian point of view, suppose your prior distribution for the parameter is . Show that your Bayesian point estimator of for the loss function is given by
Find a constant depending on such that the posterior probability that is equal to .
[The density of the distribution is , for
Paper 4, Section II, E
Consider a collection of independent random variables with common density function depending on a real parameter . What does it mean to say is a sufficient statistic for ? Prove that if the joint density of satisfies the factorisation criterion for a statistic , then is sufficient for .
Let each be uniformly distributed on . Find a two-dimensional sufficient statistic . Using the fact that is an unbiased estimator of , or otherwise, find an unbiased estimator of which is a function of and has smaller variance than . Clearly state any results you use.
Paper 1, Section I,
What does it mean to say that an estimator of a parameter is unbiased?
An -vector of observations is believed to be explained by the model
where is a known matrix, is an unknown -vector of parameters, , and is an -vector of independent random variables. Find the maximum-likelihood estimator of , and show that it is unbiased.
Paper 1, Section II, H
What is the critical region of a test of the null hypothesis against the alternative ? What is the size of a test with critical region What is the power function of a test with critical region ?
State and prove the Neyman-Pearson Lemma.
If are independent with distribution, and , find the form of the most powerful size- test of against . Find the power function as explicitly as you can, and prove that it is increasing in . Deduce that the test you have constructed is a size- test of against .
Paper 2, Section II, H
What does it mean to say that the random -vector has a multivariate normal distribution with mean and covariance matrix ?
Suppose that , and that for each is a matrix. Suppose further that
for . Prove that the random vectors are independent, and that has a multivariate normal distribution.
[Hint: Random vectors are independent if their joint is the product of their individual MGFs.]
If is an independent sample from a univariate distribution, prove that the sample variance and the sample mean are independent.
Paper 3, Section , H
In a demographic study, researchers gather data on the gender of children in families with more than two children. For each of the four possible outcomes of the first two children in the family, they find 50 families which started with that pair, and record the gender of the third child of the family. This produces the following table of counts:
First two children Third child Third child
In view of this, is the hypothesis that the gender of the third child is independent of the genders of the first two children rejected at the level?
[Hint: the point of a distribution is , and the point of a distribution is
Paper 4, Section II, H
What is a sufficient statistic? State the factorization criterion for a statistic to be sufficient.
Suppose that are independent random variables uniformly distributed over , where the parameters are not known, and . Find a sufficient statistic for the parameter based on the sample . Based on your sufficient statistic, derive an unbiased estimator of .
A Bayesian statistician observes a random sample drawn from a distribution. He has a prior density for the unknown parameters of the form
where and are constants which he chooses. Show that after observing his posterior density is again of the form
where you should find explicitly the form of and .
If is a sample from a density with unknown, what is a confidence set for ?
In the case where the are independent random variables with known, unknown, find (in terms of ) how large the size of the sample must be in order for there to exist a confidence interval for of length no more than some given .
[Hint: If then
1.II.18H
Suppose that is a sample of size with common distribution, and is an independent sample of size from a distribution.
(i) Find (with careful justification) the form of the size- likelihood-ratio test of the null hypothesis against alternative unrestricted.
(ii) Find the form of the size- likelihood-ratio test of the hypothesis
against unrestricted, where is a given constant.
Compare the critical regions you obtain in (i) and (ii) and comment briefly.
2.II.19H
Suppose that the joint distribution of random variables taking values in is given by the joint probability generating function
where the unknown parameters and are positive, and satisfy the inequality . Find . Prove that the probability mass function of is
and prove that the maximum-likelihood estimators of and based on a sample of size drawn from the distribution are
where (respectively, ) is the sample mean of (respectively, ).
By considering or otherwise, prove that the maximum-likelihood estimator is biased. Stating clearly any results to which you appeal, prove that as , making clear the sense in which this convergence happens.
4.II.19H
(i) Consider the linear model
where observations , depend on known explanatory variables , , and independent random variables .
Derive the maximum-likelihood estimators of and .
Stating clearly any results you require about the distribution of the maximum-likelihood estimators of and , explain how to construct a test of the hypothesis that against an unrestricted alternative.
(ii) A simple ballistic theory predicts that the range of a gun fired at angle of elevation should be given by the formula
where is the muzzle velocity, and is the gravitational acceleration. Shells are fired at 9 different elevations, and the ranges observed are as follows:
The model
is proposed. Using the theory of part (i) above, find expressions for the maximumlikelihood estimators of and .
The -test of the null hypothesis that against an unrestricted alternative does not reject the null hypothesis. Would you be willing to accept the model ? Briefly explain your answer.
[You may need the following summary statistics of the data. If , then 17186. ]
1.I.7C
Let be independent, identically distributed random variables from the distribution where and are unknown. Use the generalized likelihood-ratio test to derive the form of a test of the hypothesis against .
Explain carefully how the test should be implemented.
1.II.18C
Let be independent, identically distributed random variables with
where is an unknown parameter, , and . It is desired to estimate the quantity .
(i) Find the maximum-likelihood estimate, , of .
(ii) Show that is an unbiased estimate of and hence, or otherwise, obtain an unbiased estimate of which has smaller variance than and which is a function of .
(iii) Now suppose that a Bayesian approach is adopted and that the prior distribution for , is taken to be the uniform distribution on . Compute the Bayes point estimate of when the loss function is .
[You may use that fact that when are non-negative integers,
2.II.19C
State and prove the Neyman-Pearson lemma.
Suppose that is a random variable drawn from the probability density function
where and is unknown. Find the most powerful test of size , , of the hypothesis against the alternative . Express the power of the test as a function of .
Is your test uniformly most powerful for testing against Explain your answer carefully.
3.I.8C
Light bulbs are sold in packets of 3 but some of the bulbs are defective. A sample of 256 packets yields the following figures for the number of defectives in a packet:
\begin{tabular}{l|cccc} No. of defectives & 0 & 1 & 2 & 3 \ \hline No. of packets & 116 & 94 & 40 & 6 \end{tabular}
Test the hypothesis that each bulb has a constant (but unknown) probability of being defective independently of all other bulbs.
[Hint: You may wish to use some of the following percentage points:
4.II.19C
Consider the linear regression model
where are independent, identically distributed are known real numbers with and and are unknown.
(i) Find the least-squares estimates and of and , respectively, and explain why in this case they are the same as the maximum-likelihood estimates.
(ii) Determine the maximum-likelihood estimate of and find a multiple of it which is an unbiased estimate of .
(iii) Determine the joint distribution of and .
(iv) Explain carefully how you would test the hypothesis against the alternative .
A random sample is taken from a normal distribution having unknown mean and variance 1. Find the maximum likelihood estimate for based on .
Suppose that we now take a Bayesian point of view and regard itself as a normal random variable of known mean and variance . Find the Bayes' estimate for based on , corresponding to the quadratic loss function .
1.II.18C
Let be a random variable whose distribution depends on an unknown parameter . Explain what is meant by a sufficient statistic for .
In the case where is discrete, with probability mass function , explain, with justification, how a sufficient statistic may be found.
Assume now that , where are independent nonnegative random variables with common density function
Here is unknown and is a known positive parameter. Find a sufficient statistic for and hence obtain an unbiased estimator for of variance .
[You may use without proof the following facts: for independent exponential random variables and , having parameters and respectively, has mean and variance and has exponential distribution of parameter .]
2.II.19C
Suppose that are independent normal random variables of unknown mean and variance 1 . It is desired to test the hypothesis against the alternative . Show that there is a uniformly most powerful test of size and identify a critical region for such a test in the case . If you appeal to any theoretical result from the course you should also prove it.
[The 95th percentile of the standard normal distribution is 1.65.]
3.I.8C
One hundred children were asked whether they preferred crisps, fruit or chocolate. Of the boys, 12 stated a preference for crisps, 11 for fruit, and 17 for chocolate. Of the girls, 13 stated a preference for crisps, 14 for fruit, and 33 for chocolate. Answer each of the following questions by carrying out an appropriate statistical test.
(a) Are the data consistent with the hypothesis that girls find all three types of snack equally attractive?
(b) Are the data consistent with the hypothesis that boys and girls show the same distribution of preferences?
4.II.19C
Two series of experiments are performed, the first resulting in observations , the second resulting in observations . We assume that all observations are independent and normally distributed, with unknown means in the first series and in the second series. We assume further that the variances of the observations are unknown but are all equal.
Write down the distributions of the sample mean and sum of squares .
Hence obtain a statistic to test the hypothesis against and derive its distribution under . Explain how you would carry out a test of size .
The fast-food chain McGonagles have three sizes of their takeaway haggis, Large, Jumbo and Soopersize. A survey of 300 randomly selected customers at one branch choose 92 Large, 89 Jumbo and 119 Soopersize haggises.
Is there sufficient evidence to reject the hypothesis that all three sizes are equally popular? Explain your answer carefully.
1.II.18D
In the context of hypothesis testing define the following terms: (i) simple hypothesis; (ii) critical region; (iii) size; (iv) power; and (v) type II error probability.
State, without proof, the Neyman-Pearson lemma.
Let be a single observation from a probability density function . It is desired to test the hypothesis
with and , where is the distribution function of the standard normal, .
Determine the best test of size , where , and express its power in terms of and .
Find the size of the test that minimizes the sum of the error probabilities. Explain your reasoning carefully.
2.II.19D
Let be a random sample from a probability density function , where is an unknown real-valued parameter which is assumed to have a prior density . Determine the optimal Bayes point estimate of , in terms of the posterior distribution of given , when the loss function is
where and are given positive constants.
Calculate the estimate explicitly in the case when is the density of the uniform distribution on and .
3.I.8D
Let be a random sample from a normal distribution with mean and variance , where and are unknown. Derive the form of the size- generalized likelihood-ratio test of the hypothesis against , and show that it is equivalent to the standard -test of size .
[You should state, but need not derive, the distribution of the test statistic.]
4.II.19D
Let be observations satisfying
where are independent random variables each with the distribution. Here are known but and are unknown.
(i) Determine the maximum-likelihood estimates of .
(ii) Find the distribution of .
(iii) By showing that and are independent, or otherwise, determine the joint distribution of and .
(iv) Explain carefully how you would test the hypothesis against .
1.I.10H
Use the generalized likelihood-ratio test to derive Student's -test for the equality of the means of two populations. You should explain carefully the assumptions underlying the test.
1.II.21H
State and prove the Rao-Blackwell Theorem.
Suppose that are independent, identically-distributed random variables with distribution
where , is an unknown parameter. Determine a one-dimensional sufficient statistic, , for .
By first finding a simple unbiased estimate for , or otherwise, determine an unbiased estimate for which is a function of .
2.I.10H
A study of 60 men and 90 women classified each individual according to eye colour to produce the figures below.
\begin{tabular}{|c|c|c|c|} \cline { 2 - 4 } \multicolumn{1}{c|}{} & Blue & Brown & Green \ \hline Men & 20 & 20 & 20 \ \hline Women & 20 & 50 & 20 \ \hline \end{tabular}
Explain how you would analyse these results. You should indicate carefully any underlying assumptions that you are making.
A further study took 150 individuals and classified them both by eye colour and by whether they were left or right handed to produce the following table.
\begin{tabular}{|c|c|c|c|} \cline { 2 - 4 } \multicolumn{1}{c|}{} & Blue & Brown & Green \ \hline Left Handed & 20 & 20 & 20 \ \hline Right Handed & 20 & 50 & 20 \ \hline \end{tabular}
How would your analysis change? You should again set out your underlying assumptions carefully.
[You may wish to note the following percentiles of the distribution.
2.II.21H
Defining carefully the terminology that you use, state and prove the NeymanPearson Lemma.
Let be a single observation from the distribution with density function
for an unknown real parameter . Find the best test of size , of the hypothesis against , where .
When , for which values of and will the power of the best test be at least ?
4.I
Suppose that are independent random variables, with having the normal distribution with mean and variance ; here are unknown and are known constants.
Derive the least-squares estimate of .
Explain carefully how to test the hypothesis against .
4.II.19H
It is required to estimate the unknown parameter after observing , a single random variable with probability density function ; the parameter has the prior distribution with density and the loss function is . Show that the optimal Bayesian point estimate minimizes the posterior expected loss.
Suppose now that and , where is known. Determine the posterior distribution of given .
Determine the optimal Bayesian point estimate of in the cases when
(i) , and
(ii) .
Derive the least squares estimators and for the coefficients of the simple linear regression model
where are given constants, , and are independent with .
A manufacturer of optical equipment has the following data on the unit cost (in pounds) of certain custom-made lenses and the number of units made in each order:
\begin{tabular}{l|ccccc} No. of units, & 1 & 3 & 5 & 10 & 12 \ \hline Cost per unit, & 58 & 55 & 40 & 37 & 22 \end{tabular}
Assuming that the conditions underlying simple linear regression analysis are met, estimate the regression coefficients and use the estimated regression equation to predict the unit cost in an order for 8 of these lenses.
[Hint: for the data above, .]
1.II.12H
Suppose that six observations are selected at random from a normal distribution for which both the mean and the variance are unknown, and it is found that , where . Suppose also that 21 observations are selected at random from another normal distribution for which both the mean and the variance are unknown, and it is found that . Derive carefully the likelihood ratio test of the hypothesis against and apply it to the data above at the level.
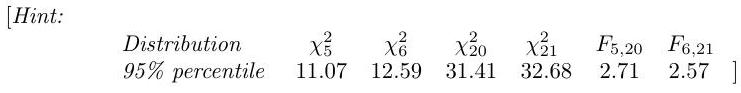
2.I.3H
Let be a random sample from the distribution, and suppose that the prior distribution for is , where are known. Determine the posterior distribution for , given , and the best point estimate of under both quadratic and absolute error loss.
2.II.12H
An examination was given to 500 high-school students in each of two large cities, and their grades were recorded as low, medium, or high. The results are given in the table below.
\begin{tabular}{l|ccc} & Low & Medium & High \ \hline City A & 103 & 145 & 252 \ City B & 140 & 136 & 224 \end{tabular}
Derive carefully the test of homogeneity and test the hypothesis that the distributions of scores among students in the two cities are the same.
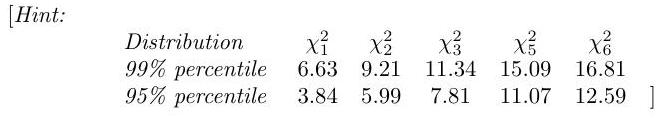
4.I.3H
The following table contains a distribution obtained in 320 tosses of 6 coins and the corresponding expected frequencies calculated with the formula for the binomial distribution for and .
\begin{tabular}{l|rrrrrrr} No. heads & 0 & 1 & 2 & 3 & 4 & 5 & 6 \ \hline Observed frequencies & 3 & 21 & 85 & 110 & 62 & 32 & 7 \ Expected frequencies & 5 & 30 & 75 & 100 & 75 & 30 & 5 \end{tabular}
Conduct a goodness-of-fit test at the level for the null hypothesis that the coins are all fair.
[Hint:
4.II.12H
State and prove the Rao-Blackwell theorem.
Suppose that are independent random variables uniformly distributed over . Find a two-dimensional sufficient statistic for . Show that an unbiased estimator of is .
Find an unbiased estimator of which is a function of and whose mean square error is no more than that of .
State the factorization criterion for sufficient statistics and give its proof in the discrete case.
Let form a random sample from a Poisson distribution for which the value of the mean is unknown. Find a one-dimensional sufficient statistic for .
Explain what is meant by a uniformly most powerful test, its power function and size.
Let be independent identically distributed random variables with common density . Obtain the uniformly most powerful test of against alternatives and determine the power function of the test.
1.II.12H
Suppose we ask 50 men and 150 women whether they are early risers, late risers, or risers with no preference. The data are given in the following table.
Derive carefully a (generalized) likelihood ratio test of independence of classification. What is the result of applying this test at the level?
2.II.12H
For ten steel ingots from a production process the following measures of hardness were obtained:
On the assumption that the variation is well described by a normal density function obtain an estimate of the process mean.
The manufacturer claims that he is supplying steel with mean hardness 75 . Derive carefully a (generalized) likelihood ratio test of this claim. Knowing that for the data above
what is the result of the test at the significance level?
4.I.3H
From each of 100 concrete mixes six sample blocks were taken and subjected to strength tests, the number out of the six blocks failing the test being recorded in the following table:
On the assumption that the probability of failure is the same for each block, obtain an unbiased estimate of this probability and explain how to find a confidence interval for it.
4.II.12H
Explain what is meant by a prior distribution, a posterior distribution, and a Bayes estimator. Relate the Bayes estimator to the posterior distribution for both quadratic and absolute error loss functions.
Suppose are independent identically distributed random variables from a distribution uniform on , and that the prior for is uniform on .
Calculate the posterior distribution for , given , and find the point estimate for under both quadratic and absolute error loss function.
1.I.3D
Let be independent, identically distributed random variables, .
Find a two-dimensional sufficient statistic for , quoting carefully, without proof, any result you use.
What is the maximum likelihood estimator of ?
1.II.12D
What is a simple hypothesis? Define the terms size and power for a test of one simple hypothesis against another.
State, without proof, the Neyman-Pearson lemma.
Let be a single random variable, with distribution . Consider testing the null hypothesis is standard normal, , against the alternative hypothesis is double exponential, with density .
Find the test of size , which maximises power, and show that the power is , where and is the distribution function of .
[Hint: if
2.I.3D
Suppose the single random variable has a uniform distribution on the interval and it is required to estimate with the loss function
where .
Find the posterior distribution for and the optimal Bayes point estimate with respect to the prior distribution with density .
2.II.12D
What is meant by a generalized likelihood ratio test? Explain in detail how to perform such a test
Let be independent random variables, and let have a Poisson distribution with unknown mean .
Find the form of the generalized likelihood ratio statistic for testing , and show that it may be approximated by
where .
If, for , you found that the value of this statistic was , would you accept ? Justify your answer.
4.I.3D
Consider the linear regression model
, where are given constants, and are independent, identically distributed , with unknown.
Find the least squares estimator of . State, without proof, the distribution of and describe how you would test against , where is given.
4.II.12D
Let be independent, identically distributed random variables, where and are unknown.
Derive the maximum likelihood estimators of , based on . Show that and are independent, and derive their distributions.
Suppose now it is intended to construct a "prediction interval" for a future, independent, random variable . We require
with the probability over the joint distribution of .
Let
By considering the distribution of , find the value of for which